Have you ever worked with a spectrophotometer in chemistry class?
The machine allows you to view the light wavelengths, otherwise known as spectra, of different objects. It is used within the chemistry fields in order to identify the different elements present in a compound. A classic experiment often done in laboratories is the flame test, where certain metal atoms evaporate in a flame, emitting unique colors characteristic to that element.
But what does this have to do with machine learning?
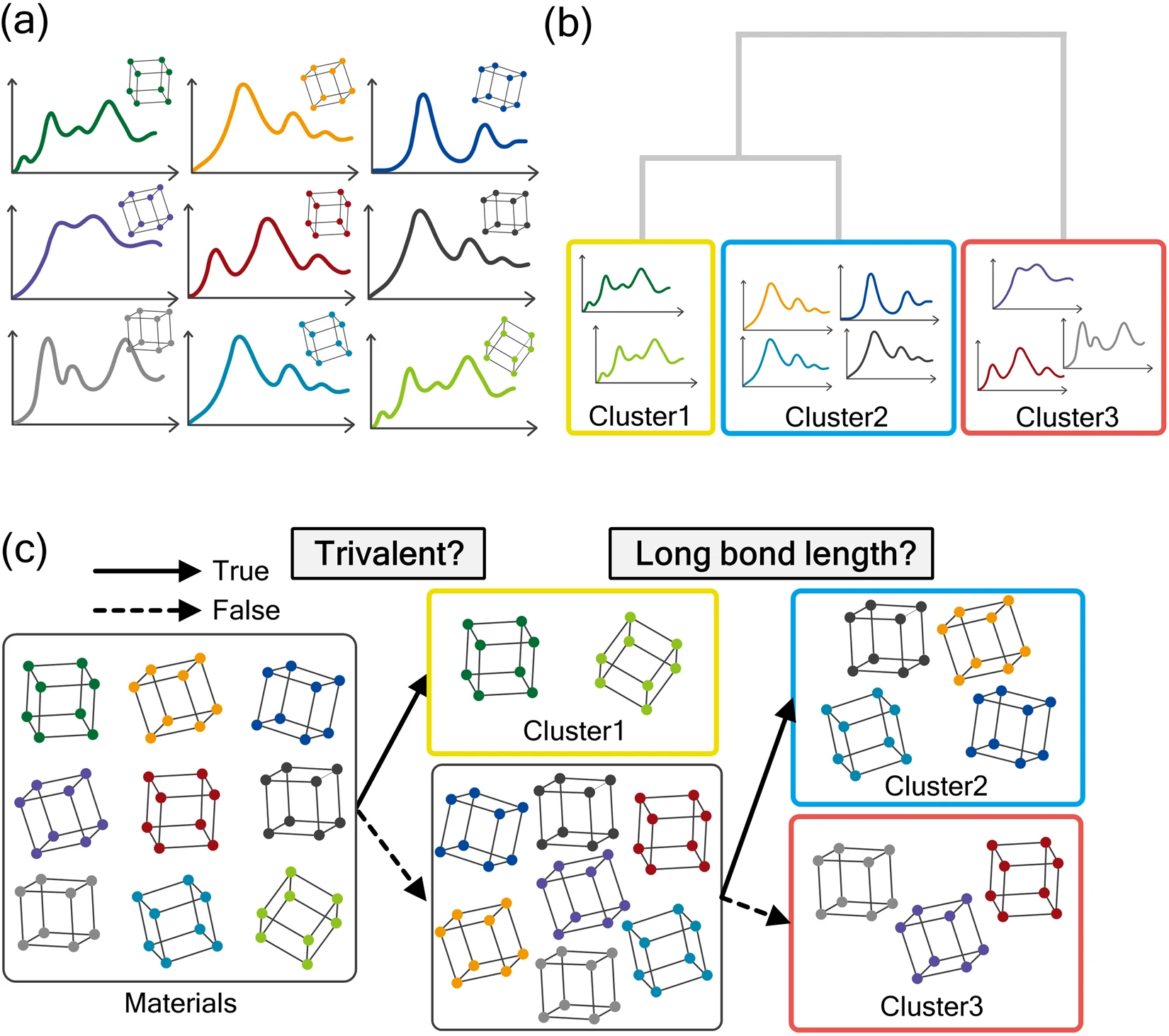
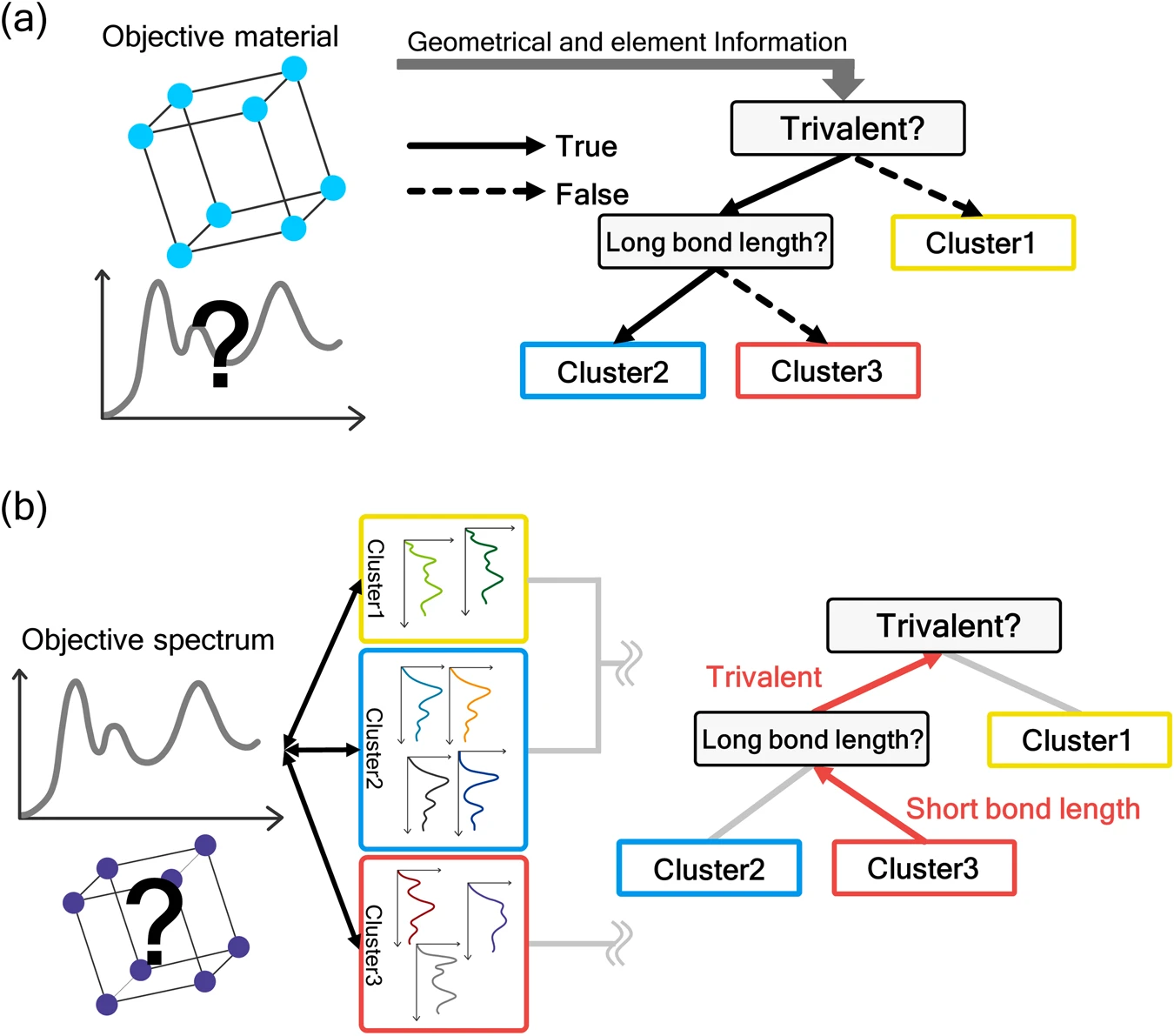
A team of researchers at the University of Tokyo used a data-driven approach to automating the analysis of unknown elements based on their light spectra by comparing the spectra to those of known samples. They believe that the use of machine learning will allow them to find unique properties of light spectra that cannot be analyzed manually or from a geometric perspective. As for the methods, they mainly used a combination of clustering and decision tree techniques.
Similar to how the brain works, a decision tree is a machine learning model that resembles a series of rule sets that the model infers from the data. That data is then used to predict new data. With the numerous features that the unknown elements in the sample have—such as the valency, bond length, and periodic table group number—the decision tree can efficiently cluster the unknown spectra into groups based on comparing the material features to similar spectra.
Sources:
What’s up to every one, as I am in fact eager of reading this web site’s post to be updated regularly. It includes nice stuff.
Really informative article. thanks!
I was reading some of your posts on this internet site and I conceive this site is rattling informative! Keep on putting up.
I’ve learned some new things through your site. One other thing I’d prefer to say is the fact newer computer operating systems usually allow much more memory to be utilized, but they as well demand more memory space simply to run. If an individual’s computer can not handle extra memory plus the newest application requires that storage increase, it is usually the time to shop for a new Laptop or computer. Thanks
I think this is one of the most vital information for me. And i’m glad reading your article. But wanna remark on some general things, The web site style is perfect, the articles is really nice : D. Good job, cheers
I really appreciate your help with my project!
Whats up very cool web site!! Man .. Beautiful .. Superb .. I will bookmark your web site and take the feeds additionally…I am happy to find a lot of useful information here in the put up, we want develop extra techniques on this regard, thank you for sharing.
It’s nearly impossible to find knowledgeable men and women during this topic, but you appear to be there’s more you’re speaking about! Thanks
I had to refresh the page times to view this page for some reason, however, the information here was worth the wait.
These are in fact wonderful ideas in about blogging. You have touched some good points here. Any way keep up wrinting.
You actually make it appear really easy along with your presentation however I find this matter to be actually something that I think I would by no means understand. It kind of feels too complex and extremely huge for me. I am having a look ahead on your next submit, I’ll attempt to get the dangle of it!
Like!! Great article post.Really thank you! Really Cool.